Saffron – Knowledge Extraction Framework
Saffron provides knowledge extraction for English from text using natural language processing. Saffron is a highly configurable open source framework that is available through command line or Web interface.
Features

Term Extraction
Given a collection of texts written in English, the term extraction phase of Saffron automatically identifies and extracts concepts that are relevant for the domain of the dataset, allowing you to get a quick insight on the content of your dataset.
Taxonomy Extraction
This component allows to organise together the terms extracted from the dataset by way of taxonomic relations, and gives a representation of the domain knowledge.
Expert Finding and Community Identification
Saffron identifies experts among the authors of documents through automatic analysis of terminology and ranking of authors. In addition, the expert finding stage of Saffron identifies communities of experts by automatic grouping, again based on their use of automatically extracted terminology.
Saffron adds value across domains
Saffron applications range from expert finding and community detection to text analytics, enterprise search and recommender systems. See Applications for a more detailed list of possible uses of Saffron and Use Cases for an insight into previous and current Saffron projects.
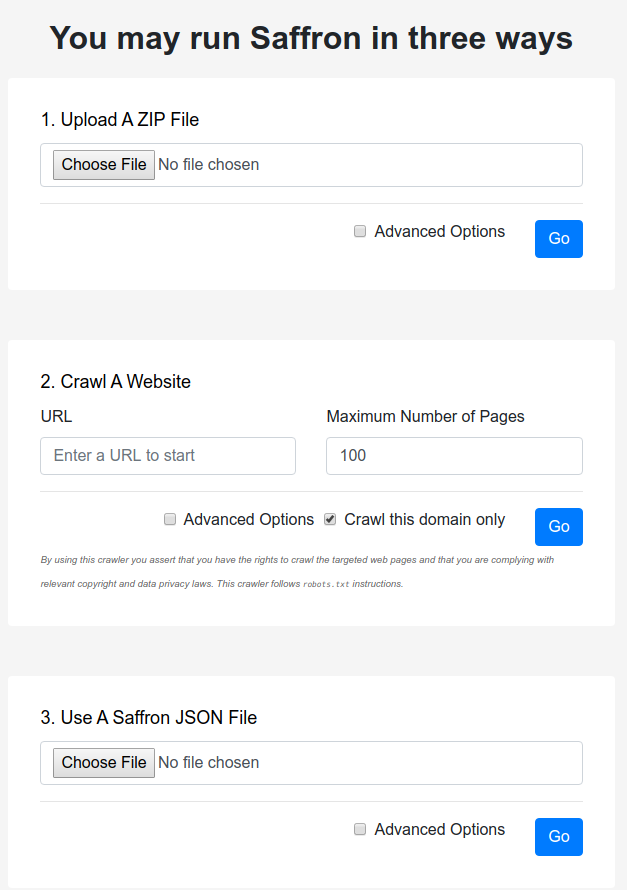
How it works
Saffron has a modular architecture and can be used off-the-shelf. Importantly, you do not need to provide any other external data other than the dataset to be analysed.
Join the community
Saffron is available on Github, contribute and be part of the community!
